在卷积神经网络中介绍了计算机视觉领域常用的深度学习模型,并实践了简单的图像分类。先描述目标检测的流程与方法,再使用全卷积网络对图像做语义分割,之后用样式迁移技术生成图像。
图像增广
1、扩大样本数据集;2、随机改变训练样本可降低模型对某些属性的依赖。两者均为了提高模型的泛化性。
常用方法:翻转和裁剪、变化颜色、叠加多个图像增广方法;
为了在预测时获得准确结果,图像增广通常仅用于训练集,而不在预测时使用含随机操作的图像增广。
Gluon数据集提供的transform模块中,transform_first函数将图像增广应用在每个训练样本(图像和标签)的第一个元素,即图像之上。
用增广后图像训练模型:
1、定义try_all_gpus函数,获取所有能用的GPU;
2、定义辅助函数_get_batch将小批量数据样本batch划分,并复制到ctx变量所指定的各个显存上;
3、定义evaluate_accuracy函数来评价模型的分类准确性,该函数通过辅助函数_get_batch使用ctx变量所包含的所有GPU来评价模型;
4、定义train函数使用多GPU训练并评价模型;
5、最终定义train_with_data_aug函数,来使用图像增广来训练模型;该函数获取所有GPU,并将Adam算法作为训练优化算法,之后将图像增广应用于训练数据集上,最后调用刚定义的train函数训练并评价模型。
1 | def train_with_data_aug(train_augs, test_augs, lr = 0.001): |
图像微调
由于收集数据所需要的成本较高,应用迁移学习:将从源数据集学到的知识迁移到目标数据集上。例:可从图形数据集训练的模型中抽取较通用的模型特征,边缘、纹理、形状、物体组成识别等等。
微调时常用的一种迁移学习技术,当目标数据集远小于源数据集时,微调有助于提升模型的泛化能力,步骤包括:
1、在源数据集上预训练一个神经网络模型,即源模型;
2、创建一个新的神经网络模型,即目标模型,其复制了源模型上除了输出层以外的所有模型设计与参数。假设该模型参数包含了源数据集上学习到的知识,且同样适用于目标数据集。
3、为目标模型添加一个输出大小为目标数据集类别个数的输出层,并初始化该层的模型参数。
4、在目标数据集上训练目标模型,将从头训练输出层,而其余层的参数将会基于源模型的参数微调得到。
热狗识别
基于一个小数据集对在ImageNet数据集上训练好的ResNet模型进行微调。
1、获取数据集;
2、定义和初始化模型:使用在ImageNet数据集上预训练的ResNet-18作为源模型,该源模型实例含有两个成员变量,即features和output。前者包括模型输出层以外的所有层,后者为模型的输出层,这样的划分方便微调除输出层以外所有层的模型参数。
3、微调模型:先定义一个使用微调的训练函数train_fine_tuning,以便多次调用。
1 | def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5): |
一般来说,微调参数会使用较小的学习率;而从头训练输出层可以使用较大学习率。
目标检测与边界框
在图像分类任务里,假设只有一个主体目标;而目标检测往往是图像中有多个感兴趣的目标。
目标检测算法通常会在输入图像中采样大量的区域,,然后判断是否包含感兴趣的目标,并调整区域边缘从而更准确地预测目标的真是边界框。
锚框:以每个像素为中心生成多个大小和宽高比不同的边界框。
交并比:(若某个锚框较好地覆盖了图像的狗,那么较好该如何量化)直观的方法是,衡量锚框与真实边界框间的相似度Jaccard系数可以衡量两个集合的相似度,Jaccard系数等于二者交集大小除以二者并集大小。
在训练集中,将每一个锚框视为一个训练样本,为了训练目标检测模型,需为每个锚框标注两个标签:1、锚框所含目标的类别;2、真实边界框相对锚框的便宜量offset。
在目标检测的训练集中,每个图像已经标注了真实边界框的位置及所含目标的类别,那么生成锚框后,如何为锚框分配与其相似的真实边界框呢?
分配真实边界框
1、锚框有Na个,真实边界框有Nb个,定义矩阵为Na X Nb,其第i列第j行的元素为锚框Ai与真实边界框Bj的交并比。则通过不停找出矩阵最大元素,且每找出一个元素则丢弃该行列的元素,直至矩阵丢弃完,只剩Na - Nb个锚框。
2、遍历剩下的锚框,只有该交并比大于预先设定的阈值时,才为锚框分配真实边界框Bj。
3、如果一个锚框A被分配了真实边界框B,将A的类别设为B的类别,并根据B和A的中心坐标的相对位置以及两个框的相对大小为锚框A标注偏移量。如果一个锚框没有被分配真实边界框,需将该锚框的类别设为背景,称为负类锚框。
4、通过contrib.nd模块中的MultiBoxTarget函数来为锚框标注偏移量和类别。该函数将背景设定为0,并从令0开始的目标类别的整数索引自加1,并通过expand_dims函数为锚框和真实边界添加样本维,并构造形状为(批量大小,包括背景的类别个数,锚框数)的任意预测结果。
非极大值抑制
当锚框数量较多时,同一目标可能输出较多相似的。用非极大值抑制来移除:对一个预测边界框B,模型会计算其各个类别的预测概率,其中最大概率对应的类别即B的预测类别,且在同一图像上将预测类别置信度从高到低排列,得到列表L。从L中选取置信度最高的预测边界框B1为基准,将与B1交并比大于某阈值的从L中移除,阈值为预定的超参数,此时L保留了置信度最高的边界框并移除了与之相似的其他预测边界框。
多尺度目标检测
如果以图像每个像素中心都生成锚框,很容易生成过多锚框而造成计算量过大,方法一:在输入图像中均匀采样一小部分像素,并以采样的像素为中心生成锚框。之后既然我们已经在不同尺度下生成了不同大小的锚框,相应的需要在不同尺度下检测不同大小的目标,基于卷积神经网络有如下的方法:
在某尺度下,假设我们根据Ci张形状为h X w的特征图生成h X w组不同中心的锚框,且每组锚框的个数为a。
假设这里的Ci张特征图为卷积神经网络根据输入图像做前向运算所得的中间输出,根据感受野的定义,特征图在相同位置的Ci个单元在输入图像的感受野相同且表征了同一感受野内的输入图像信息。因此我们将这Ci个单元变换为该位置为中心生成的a个锚框的类别和偏移量,故本质上使用感受野内的信息来预测锚框。
因此不同大小的感受野用于检测不同大小的目标,可通过设计网络来控制输出层感受野大小,从而分别用来检测不同大小的目标。
单发多框检测
由一个基础网络块和若干多尺度特征块串联而成。其中网络块用于从原始图像中抽取特征,因此一般会选择常用的深度卷积神经网络,例如:在分类层之前截断的VGG、或者用ResNet替代。
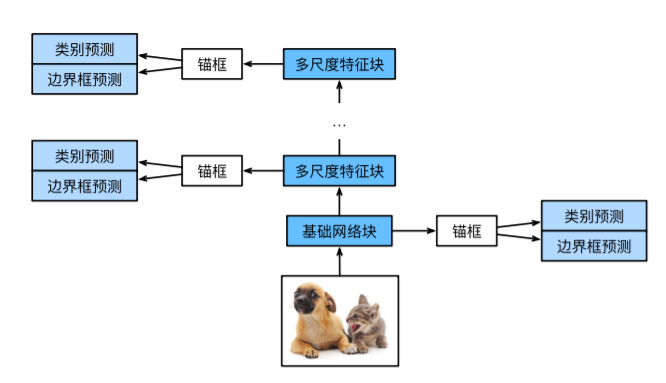
设计基础网络,使其输出的高宽较大,这样一来基于该特征图生成的锚框数量较多,用于检测较小目标;接下来每个多尺度特征块将上一层提供的特征图的高、宽减小,使感受野变广阔,这样越靠顶部其特征图越小,生成锚框越少,适合检测尺寸大的目标。借此,单发多框检测是一个多尺度的目标检测。
类别预测层
如果用全连接层作为输出,容易导致模型参数过多,故像NIN一样使用卷积层的通道进行输出类别的预测,来降低模型复杂度。即使用一个保持输入高、宽的卷积层,使输入、输出的空间坐标一一对应
边界预测层
设计与类预测层类似,需要为每个锚框预测4个偏移量。
连接多尺度的预测
由于每个尺度的特征图形状与锚框个数都可能不同,因此不同尺度预测输出形状可能不同。需要将他们变形成统一的格式并将多尺度的预测连结,从而让后续的计算更简单。
高、宽减半块
为了能多尺度地检测目标,需要定义高宽减半块,其串联了两个填充为1的3X3卷积层和步幅为2的2X2最大池化层,卷积层不改变特征图形状,而后面池化层将特征图的高、宽减半。
基础网络块
用于在原始图像中抽取特征,此处串联3个高、宽减半块,并将通道数翻倍,则当输入图像形状为256X256时,基础网络块的输出特征图的形状为32X32。
完整的模型
单发多框检测一共包括5个模块,每个模块即生成锚框,又来预测锚框的类别与偏移量。第一模块为基础网络块,二至四模块为高宽减半块,第五模块使用全局最大池化层将高和宽降到1。
单发多框检测训练模型
1、读取数据集并初始化;
2、定义损失函数与评价函数:
一、有关锚框类别的损失,图像分类问题一般使用的:交叉熵函数
二、有关正类锚框偏移量的损失:预测偏移量是一个回归问题,因此不用平方损失,而用L1范数损失,即预测值与真实值之间差的绝对值。
3、训练模型
在模型的前向计算过程中生成多尺度的锚框anchors,并为每个锚框预测类别cls_preds和偏移量bbox_preds,之后根据标签信息Y为生成的每个锚框标注类别和偏移量。最后,根据这两者值来计算损失函数。
4、预测目标
在预测阶段,我们读取图像并变换尺寸,转换为卷积层所需的四维格式,通过MultiBoxDetection函数根据锚框及其预测偏移量得到预测边界框,并通过非极大值抑制移除相似的预测边界框;最后,将置信度不低于0.3的边界框筛选为最终输出。
区域卷积神经网络R-CNN
R-CNN首先对图像选取若干提议区域,并标注它们的类别和边界框,之后用卷积神经网络对每个提议区域做前向运算来抽取特征。
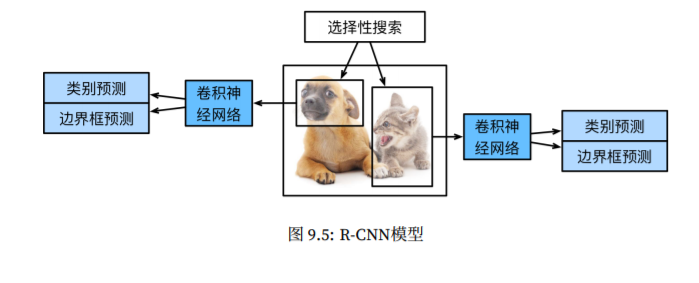
1、对输入图像进行选择性搜索,来选取多个高质量的提议区域,通常在多个尺度下选取,并标注类别与真实边界框;
2、选取一个预训练的卷积神经网络,并将其在输出层之前截断,并将每个提议区域变形为网络所需要的尺寸,并通过前向计算输出抽取的提议区域特征;
3、将每个提议区域的特征连同其标注的类别作为一个文本,训练多个支持向量机对目标进行分类,其中每个支持向量机用来判断样本是否属于一个实例;
4、将每个提议区域的特征连同其标注的边界框作为一个样本,训练线性回归模型来预测真实边界框。
FAST R-CNN
R-CNN抽取的独立特征常有大量重复计算,利用FAST R-CNN进行简化,
FASTER R-CNN
将选择性搜索替换成区域提议网络,从而减少提议区域的生成数量,以达到较精确的目标检测结果。
Mask R-CNN
当训练数据还标注了每个目标在图像上的像素级位置,那么Mask R CNN模型能有效利用这些详尽的标注信息
语义分割和数据集
语义分割问题:关注如何将图像分割成属于不同语义类别的区域,且均为像素级,相比于锚框更加精确。
图像分割问题:利用像素间相关性将图像分割成若干区域,且训练时并不需要像素有关的标签信息,预测时也无法保证希望得到的语义。
实例分割问题:研究如何识别图像中各个目标实例的像素级区域,不仅要区分语义,还要区分不同目标实例,比如:区分两条同样语义的狗。
Pascal VOC2012数据集
由于语义分割的输出图像和标签在像素上一一对应,所以将图像随机裁剪成固定尺寸而不是缩放。
全卷积网络FCN
FCN实现了从图像像素到像素类别的变换;FCN通过转置卷积层,将中间层特征图的高、宽变换回输入图像的尺寸,从而令预测结果与输入图像在空间维上一一对应。
转置卷积层
构造模型
1、先使用卷积神经网络来抽取图像特征;
2、通过1X1卷积层将通道数变换成类别个数;
3、通过转置卷积层,将特征图的高、宽变换为输入图像的尺寸,使模型输出与输入图像的高、宽相同,并在空间位置一一对应,最终输出的通道中包含了该空间位置像素级别的类别预测;
样式迁移
使用卷积神经网络自动将某图像中的样式应用在另一图像上,两张输入图像:内容图像、样式图像。
具体实施
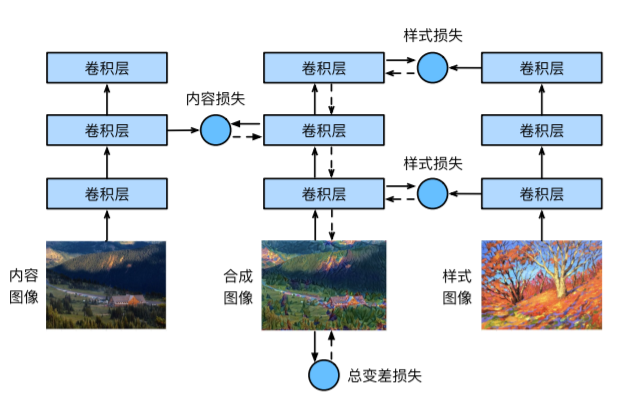
1、初始化合成图像,一般初始化成内容图像,该图像便是样式迁移过程中需要迭代的模型参数。
2、选择一个预训练的卷积网络来抽取图像的特征,其中模型参数在训练时无需更新,深度神经网络凭借多个层级逐级抽取图像的特征,可以选择其中某些层的输出作为内容特征;
3、正向传播计算样式迁移的损失函数,通过反向传播迭代模型参数,即不断更新合成图像。
预处理和后处理图像
预处理:在RGB三个通道分别做标准化,将结果变换成输入形式;
后处理:将输出图像中的像素值还原回标准化之前值;
抽取特征
使用基于ImageNet数据集训练的VGG-19模型来抽取图像特征;
定义损失函数
内容损失:利用平方误差函数衡量合成图像与样式图像在内容上差异;
样式损失:利用平方误差函数衡量合成图像与样式图像在样式上差异;
总变差损失:用于降噪,使合成图像中噪点(特别亮或特别暗的颗粒像素)减少。
损失函数为以上三者的加权和。
