1、语言模型
与多层感知机和能有效处理空间信息的卷积神经网络不同,循环神经网络是为了更好地处理时序信息而设计的。引入状态变量来存储过去的信息,并用其与当前的输入共同决定当前的输出。
语言模型:可将自然语言文本看作一段离散的时间序列,假设一段长度为T的文本中的词依次为W1、W2….Wt,那么在离散的时间序列中,Wt可看作在时间步t的输出或标签。给定一个长度为T的词的序列,语言模型将计算该序列概率:P(W1,W2,….,Wt)。为计算该语言模型,需要先计算词的概率,以及一个词在给定前几个词的情况下的条件概率。
N元语法:计算和存储多个词的概率复杂度会呈指数级增加,故通过马尔可夫假设简化语言模型:一个词的出现只与前面N个词相关,即N阶马尔可夫链。
故基于n-1阶马尔可夫链,可将语言模型改写为:
$$
P(W1,W2,…,Wt) = ∏P(Wt|Wt-(n-1),…,Wt-1)
$$
以上也叫做n元语法,当n较小时,n元语法往往不准确,当n较大时,n元语法需要计算并存储大量的词频和多词相邻频率。
2、循环神经网络
循环神经网络:并非刚性地记忆所有固定长度的序列,而是通过隐藏状态来存储之前时间步的信息。利用之前的多层感知机,通过添加隐藏状态将其变成循环神经网络。
不含隐藏状态的多层感知机:
样本数为n、输出个数为d的小批量数据样本X。设隐藏层的激活函数为f,则其输出H为:
$$
H = f(X Wxh + bh)
$$
其中隐藏层权重参数W为Rn*d,隐藏层偏差参数b为R1xh,h为隐藏单元个数。上式两者根据广播机制来相加,设输出层的输出个数为q,则输出层的输出为:
$$
O = HWhq +bq
$$
若为分类问题,可用softmax(O)来计算输出类别的概率分布。
含隐藏状态的多层感知机
与上一个相区别的是,保存上一时间步的隐藏变量Ht-1,并引入一个新的权重参数Whh为Rhxh,该参数用于描述在当前时间步如何使用上一时间步的隐藏变量。
$$
Ht = f(Xt Wxh + Ht-1Whh +bh)
$$
与多层感知机相比,添加了隐藏变量来捕捉截至当前时间步的序列的历史信息,就像神经网络当前时间步的状态或记忆一样,因此也称为隐藏状态,由于在当前时间步使用了上一时间步的隐藏状态,因此计算是循环的。通过对上一次时间步的利用,其模型参数的数量不随时间步的增加而增长。将输入与前一时间步隐藏状态连结后,输入至一个激活函数为f的全连接层,该全连接层的输出就是当前时间步的隐藏状态,且模型参数为Wxh与Whh的连结,偏差为bh。
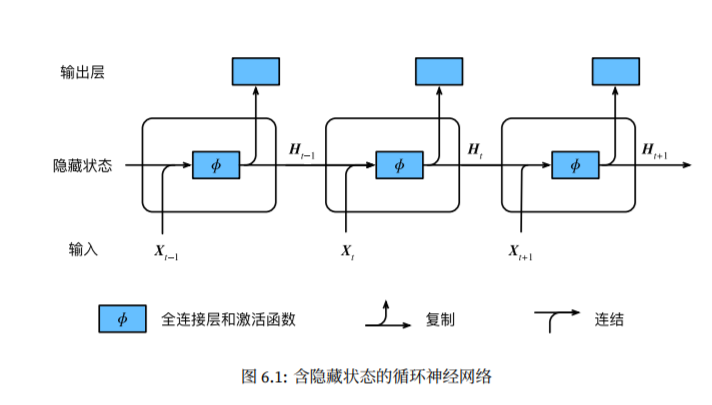 )
)
3、基于字符级神经网络的语言模型
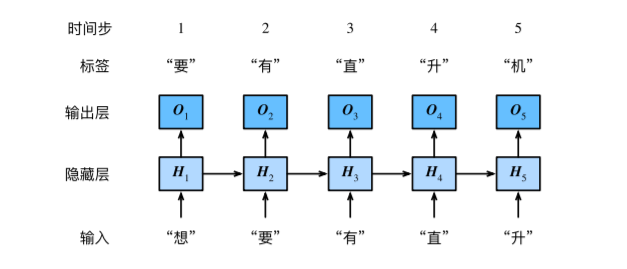
演示如何1基于当前与过去字符来预测下一个字符,训练时对每个时间步的输出层输出使用softmax运算,然后使用交叉熵损失函数来计算其与标签的误差。
处理数据集
建立字符索引:将每个字符映射成一个从0开始的连续整数,又称索引以方便后续处理。为得索引,我们将数据集中所有不同字符取出来,并逐一映射到索引来构造字典。
时序数据采样:每次随机读取小批量样本和标签,样本包含连续的字符。例:时间步数为5,样本序列为5个字符:‘’想,要,有,直,升”,则其标签序列为这些字符在训练集中的下一个字符:“要,有,直,升,机”。
随机采样:每个样本为原始序列上任意截取的一段序列,相邻的两个随机小批量不一定相邻,故每次随机采样前都需要重新初始化隐藏状态。
相邻采样:令相邻的两个随机小批量在原始序列上的位置也相毗邻,此时可以用一个小批量最终时间步的隐藏状态来初始化下一个小批量的隐藏状态:如此循环造成的影响:1、训练模型时,只需在每个迭代周期开始时初始化隐藏状态;2、当多个小批量通过传递隐藏状态串联起来时,梯度计算将依赖串联起的序列,迭代次数增加,梯度开销会越来越大。
one-hot向量
使用one-hot向量将词表示成向量输入到神经网络:每个字符已经同一个从0到N-1的连续整数值索引一一对应。如果一个字符的索引是i,则其向量为全0的长为N的向量,仅将位置为i的元素设为1。
1 | def to_one_hot(X,size): |
构建模型
先初始化模型参数,将隐藏单元个数num_hiddens作为超参数,
1 | num_inputs, num_hiddens, num_outputs = vocab_size, 256, vocab_size |
定义init_rnn_state函数来返回初始化的隐藏状态,返回由一个形状为(批量大小,隐藏单元个数)的值为0的NDArray组成的元组。
1 | def init_rnn_state(batch_size, num_hiddens, ctx): |
定义rnn函数来在一个时间步中计算隐藏状态与输出,激活函数使用tanh
1 | def rnn(inputs, state, params): |
定义预测函数
基于前缀prefix(含有数个字符的字符串)来预测接下来的num_chars个字符:
1 | def predict_rnn(prefix, num_chars, rnn, params, init_rnn_state, |
裁剪梯度
利用裁剪梯度以应对梯度爆炸,假设将所有模型参数梯度的元素拼接成一个向量g,并设裁剪的阈值为s;裁剪后的梯度的L2范数不超过s
$$
裁剪后的梯度为 min(s/||g|| , 1)g
$$
1 | def grad_clipping(params, theta, ctx): |
模型训练函数
困惑度用于评价语言模型的好坏,是对交叉熵损失函数做指数运算后得到的值。
与之前章节的训练函数相比,该模型训练有几点不同:1、用困惑度评价模型;2、在迭代模型参数前裁剪梯度;3、对时序数据采用不同的采样方法将导致隐藏状态初始化的不同。
使用Gluon进行模型的简洁实现
Gluon的rnn模块提供了循环神经网络的实现,
时间反向传播
不裁剪梯度时,模型将无法正常训练。我们将循环神经网络按时间步展开,从而得到模型变量与参数之间的依赖关系,并根据链式法则应用反向传播计算并存储梯度。
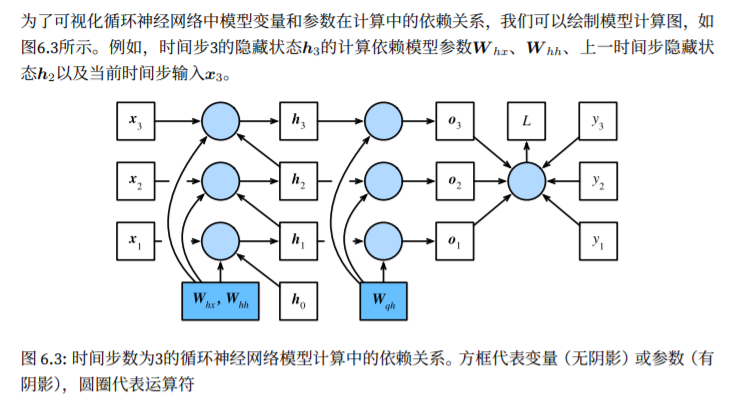
每次迭代中,我们在依次计算完以上各个梯度后,会将它们存储起来,从而避免重复计算。同时,反向传播中的梯度计算可能会依赖变量的当前值,他们正是通过正向传播计算出来的。
4、门控循环单元
裁剪梯度可以应对梯度爆炸,但是没办法解决梯度衰减的问题。因此,循环神经网络在实际中很难捕捉时间序列中时间步距离较大的依赖关系。GRU门控循环神经网络通过可以学习的门来控制信息的流动。
重置门和更新门
两者输入均为当前时间步输入Xt与上一时间步隐藏状态Ht-1,输出由激活函数为sigmoid函数的全连接层计算得到
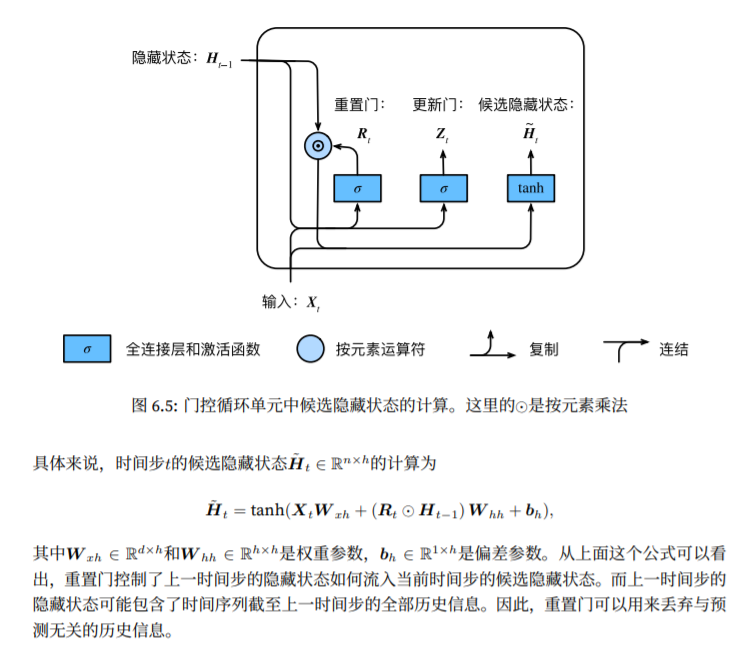
候选隐藏状态
GRU将计算候选隐藏状态来辅助稍后的隐藏状态计算,先将当前时间步重置门的输出与上一时间步重置门隐藏状态做按元素乘法。重置门中元素值接近0,则意味重置对应隐藏状态元素为0,则丢弃上一时间步的隐藏状态;若近似1,则保留上一时间步隐藏状态。
之后与当前时间步的输出连结,再通过含t激活函数tanh的全连接层计算候选隐藏状态,其所有元素值域为[-1,1]
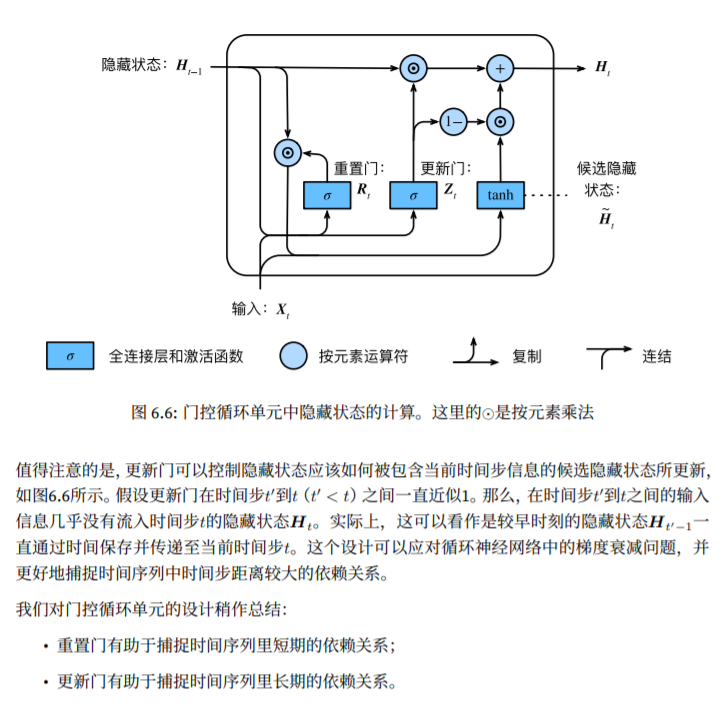
隐藏状态
最后,时间步的隐藏状态Ht的计算使用了当前时间步的更新门Zt来对上一时间步的隐藏状态Ht-1和当前时间步的候选隐藏状态Ht*来做组合:
在Gluon中可直接调用rnn模块中的GRU类来实现GRU门控循环。
LSTM长短期记忆
LSTM引入了三个门:输入门、遗忘门、输出门
在Gluon中可调用rnn模块中的LSTM类来实现长短期记忆。
5、深度循环神经网络
深度循环神经网络:目前为止介绍的循环神经网络只有一个单项的隐藏层,深度学习中通常会用到含多个隐藏层的循环神经网络,在该网络中,隐藏状态的信息不断传递至当前层的下一时间步和当前时间步的下一层。
双向循环神经网络:之前的介绍的神经网络模型都是假设当前时间步由前面的较早时间步的序列来决定,因此信息均通过隐藏状态向后传递。故双向神经网络通过增加从后往前传递信息的隐藏层来更灵活地处理这类信息。
